![]()
2024 Latest Databricks-Machine-Learning-Professional Exam Dumps Recently Updated 62 Questions
Databricks Databricks-Machine-Learning-Professional Real 2024 Braindumps Mock Exam Dumps
Databricks Databricks-Machine-Learning-Professional Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
| Topic 6 |
|
| Topic 7 |
|
| Topic 8 |
|
| Topic 9 |
|
NEW QUESTION # 30
A machine learning engineer has created a webhook with the following code block:
Which of the following code blocks will trigger this webhook to run the associate job?
- A.

- B.

- C.

- D.

- E.

Answer: A
NEW QUESTION # 31
A machine learning engineer wants to deploy a model for real-time serving using MLflow Model Serving. For the model, the machine learning engineer currently has one model version in each of the stages in the MLflow Model Registry. The engineer wants to know which model versions can be queried once Model Serving is enabled for the model.
Which of the following lists all of the MLflow Model Registry stages whose model versions are automatically deployed with Model Serving?
- A. Staging. Production. Archived
- B. None. Staging. Production. Archived
- C. Production
- D. Staging. Production
- E. [None. Staging. Production
Answer: D
NEW QUESTION # 32
A machine learning engineering team wants to build a continuous pipeline for data preparation of a machine learning application. The team would like the data to be fully processed and made ready for inference in a series of equal-sized batches.
Which of the following tools can be used to provide this type of continuous processing?
- A. MLflow
D Delta Lake - B. [Structured Streaming
- C. Spark UDFs
- D. AutoML
Answer: C
NEW QUESTION # 33
A machine learning engineer is in the process of implementing a concept drift monitoring solution. They are planning to use the following steps:
1. Deploy a model to production and compute predicted values
2. Obtain the observed (actual) label values
3. _____
4. Run a statistical test to determine if there are changes over time
Which of the following should be completed as Step #3?
- A. None of these should be completed as Step #3
- B. Retrain the model
- C. Obtain the observed values (actual) feature values
- D. Compute the evaluation metric using the observed and predicted values
- E. Measure the latency of the prediction time
Answer: A
NEW QUESTION # 34
Which of the following is a simple statistic to monitor for categorical feature drift?
- A. Mode
- B. Percentage of missing values
- C. None of these
- D. Number of unique values
- E. Mode, number of unique values, and percentage of missing values
Answer: E
NEW QUESTION # 35
Which of the following MLflow Model Registry use cases requires the use of an HTTP Webhook?
- A. None of these use cases require the use of an HTTP Webhook
- B. Starting a testing job when a new model is registered
- C. Sending an email alert when an automated testing Job fails
- D. Sending a message to a Slack channel when a model version transitions stages
- E. Updating data in a source table for a Databricks SQL dashboard when a model version transitions to the Production stage
Answer: E
NEW QUESTION # 36
A data scientist has written a function to track the runs of their random forest model. The data scientist is changing the number of trees in the forest across each run.
Which of the following MLflow operations is designed to log single values like the number of trees in a random forest?
- A. There is no way to store values like this.
- B. mlflow.log_param
- C. mlflow.log_model
- D. mlflow.log_metric
- E. mlflow.log_artifact
Answer: D
NEW QUESTION # 37
Which of the following describes the concept of MLflow Model flavors?
- A. A convention that MLflow Experiments can use to organize their Runs by project
- B. A convention that MLflow Model Registry can use to organize its Models by project
- C. A convention that deployment tools can use to wrap preprocessing logic into a Model
- D. A convention that deployment tools can use to understand the model
- E. A convention that MLflow Model Registry can use to version models
Answer: A
NEW QUESTION # 38
A machine learning engineer is manually refreshing a model in an existing machine learning pipeline. The pipeline uses the MLflow Model Registry model "project". The machine learning engineer would like to add a new version of the model to "project".
Which of the following MLflow operations can the machine learning engineer use to accomplish this task?
- A. MlflowClient.get_model_version
- B. mlflow.add_model_version
- C. mlflow.register_model
- D. The machine learning engineer needs to create an entirely new MLflow Model Registry model
- E. MlflowClient.update_registered_model
Answer: E
NEW QUESTION # 39
A machine learning engineer is converting a Hyperopt-based hyperparameter tuning process from manual MLflow logging to MLflow Autologging. They are trying to determine how to manage nested Hyperopt runs with MLflow Autologging.
Which of the following approaches will create a single parent run for the process and a child run for each unique combination of hyperparameter values when using Hyperopt and MLflow Autologging?
- A. There is no way to accomplish nested runs with MLflow Autoloqqinq and Hyperopt
- B. Starting a manual child run within the objective function
- C. Ensuring that a built-in model flavor is used for the model logging
- D. MLflow Autoloqqinq will automatically accomplish this task with Hyperopt
- E. Startinq a manual parent run before calling fmin
Answer: E
NEW QUESTION # 40
A machine learning engineer wants to move their model version model_version for the MLflow Model Registry model model from the Staging stage to the Production stage using MLflow Client client.
Which of the following code blocks can they use to accomplish the task?
- A.

- B.

- C.

- D.

- E.

Answer: E
NEW QUESTION # 41
A data scientist has developed a scikit-learn model sklearn_model and they want to log the model using MLflow.
They write the following incomplete code block:
Which of the following lines of code can be used to fill in the blank so the code block can successfully complete the task?
- A. mlflow.spark.track_model(sklearn_model, "model")
- B. mlflow.sklearn.load_model("model")
- C. mlflow.sklearn.log_model(sklearn_model, "model")
- D. mlflow.sklearn.track_model(sklearn_model, "model")
- E. mlflow.spark.log_model(sklearn_model, "model")
Answer: A
NEW QUESTION # 42
A machine learning engineer has deployed a model recommender using MLflow Model Serving. They now want to query the version of that model that is in the Production stage of the MLflow Model Registry.
Which of the following model URIs can be used to query the described model version?
- A. https://<databricks-instance>/model/recommender/stage-production/invocations
- B. https://<databricks-instance>/model/recommender/Production/invocations
- C. The version number of the model version in Production is necessary to complete this task.
- D. https://<databricks-instance>/model-serving/recommender/Production/invocations
- E. https://<databricks-instance>/model-serving/recommender/stage-production/invocations
Answer: C
NEW QUESTION # 43
A data scientist would like to enable MLflow Autologging for all machine learning libraries used in a notebook. They want to ensure that MLflow Autologging is used no matter what version of the Databricks Runtime for Machine Learning is used to run the notebook and no matter what workspace-wide configurations are selected in the Admin Console.
Which of the following lines of code can they use to accomplish this task?
- A. mlflow.autolog()
- B. spark.conf.set("autologging", True)
- C. It is not possible to automatically log MLflow runs.
- D. mlflow.spark.autolog()
- E. mlflow.sklearn.autolog()
Answer: B
NEW QUESTION # 44
Which of the following is a simple, low-cost method of monitoring numeric feature drift?
- A. Jensen-Shannon test
- B. None of these can be used to monitor feature drift
- C. Chi-squared test
- D. Kolmogorov-Smirnov (KS) test
- E. Summary statistics trends
Answer: E
NEW QUESTION # 45
A data scientist has created a Python function compute_features that returns a Spark DataFrame with the following schema:
The resulting DataFrame is assigned to the features_df variable. The data scientist wants to create a Feature Store table using features_df.
Which of the following code blocks can they use to create and populate the Feature Store table using the Feature Store Client fs?
- A.

- B.

- C. features_df.write.mode("fs").path("new_table")
- D.
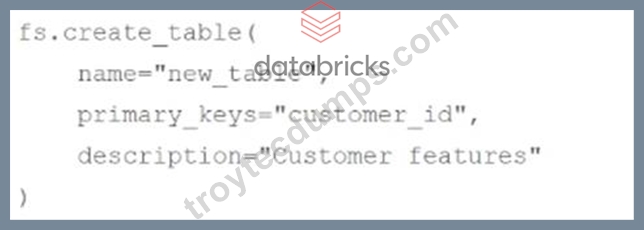
- E. features_df.write.mode("feature").path("new_table")
Answer: B
NEW QUESTION # 46
A data scientist is utilizing MLflow to track their machine learning experiments. After completing a series of runs for the experiment with experiment ID exp_id, the data scientist wants to programmatically work with the experiment run data in a Spark DataFrame. They have an active MLflow Client client and an active Spark session spark.
Which of the following lines of code can be used to obtain run-level results for exp_id in a Spark DataFrame?
- A. spark.read.format("delta").load(exp_id)
- B. client.list_run_infos(exp_id)
- C. mlflow.search_runs(exp_id)
- D. There is no way to programmatically return row-level results from an MLflow Experiment.
- E. spark.read.format("mlflow-experiment").load(exp_id)
Answer: A
NEW QUESTION # 47
A machine learning engineer and data scientist are working together to convert a batch deployment to an always-on streaming deployment. The machine learning engineer has expressed that rigorous data tests must be put in place as a part of their conversion to account for potential changes in data formats.
Which of the following describes why these types of data type tests and checks are particularly important for streaming deployments?
- A. Because the streaming deployment is always on, all types of data must be handled without producing an error
- B. None of these statements
- C. Because the streaming deployment is always on, there is a need to confirm that the deployment can autoscale
- D. All of these statements
- E. Because the streaming deployment is always on, there is no practitioner to debug poor model performance
Answer: C
NEW QUESTION # 48
A machine learning engineering team has written predictions computed in a batch job to a Delta table for querying. However, the team has noticed that the querying is running slowly. The team has already tuned the size of the data files. Upon investigating, the team has concluded that the rows meeting the query condition are sparsely located throughout each of the data files.
Based on the scenario, which of the following optimization techniques could speed up the query by colocating similar records while considering values in multiple columns?
- A. Bin-packing
- B. Z-Ordering
- C. Write as a Parquet file
- D. Tuning the file size
- E. Data skipping
Answer: D
NEW QUESTION # 49
Which of the following MLflow operations can be used to delete a model from the MLflow Model Registry?
- A. client.update_registered_model
- B. client.delete_model_version
- C. client.transition_model_version_stage
- D. client.delete_registered_model
- E. client.delete_model
Answer: D
NEW QUESTION # 50
Which of the following is an advantage of using the python_function(pyfunc) model flavor over the built-in library-specific model flavors?
- A. python_function provides no benefits over the built-in library-specific model flavors
- B. python_function can be used to store models in an MLmodel file
- C. python_function can be used to deploy models without worrying about which library was used to create the model
- D. python_function can be used to deploy models in a parallelizable fashion
- E. python_function can be used to deploy models without worrying about whether they are deployed in batch, streaming, or real-time environments
Answer: D
NEW QUESTION # 51
A machine learning engineering manager has asked all of the engineers on their team to add text descriptions to each of the model projects in the MLflow Model Registry. They are starting with the model project "model" and they'd like to add the text in the model_description variable.
The team is using the following line of code:
Which of the following changes does the team need to make to the above code block to accomplish the task?
- A. There no changes necessary
- B. Replace description with artifact
- C. Replace update_registered_model with update_model_version
- D. Add a Python model as an argument to update_registered_model
- E. Replace client.update_registered_model with mlflow
Answer: A
NEW QUESTION # 52
Which of the following is a benefit of logging a model signature with an MLflow model?
- A. The schema of input data can be validated when serving models
- B. The model can be deployed using real-time serving tools
- C. The schema of input data will be converted to match the signature
- D. The model will have a unique identifier in the MLflow experiment
- E. The model will be secured by the user that developed it
Answer: C
NEW QUESTION # 53
......
Verified Databricks-Machine-Learning-Professional Exam Dumps Q&As - Provide Databricks-Machine-Learning-Professional with Correct Answers: https://www.troytecdumps.com/Databricks-Machine-Learning-Professional-troytec-exam-dumps.html
Databricks-Machine-Learning-Professional Exam Questions | Real Databricks-Machine-Learning-Professional Practice Dumps: https://drive.google.com/open?id=15hH4x2j9VaGZcE7NMz1hE3VqQnx4tCcp